Bei einem SEO-Check Ihrer Website kann es sein, dass Sie aufgefordert werden, leere strong- und bold-Tags zu entfernen. Damit sind Textformatierungen ohne Text gemeint, die als solche natürlich schwer im Text zu finden sind. Um dies zu tun, muss der Code der Seite analysiert werden, was bei einer umfangreichen Seite sehr aufwendig sein kann.
Das folgende Python-Skript verwendet Scrapy, um eine Webseite nach leeren strong- und bold-Tags zu durchsuchen. Es crawlt die angegebenen URLs, extrahiert diese leeren Tags, speichert sie in einer Liste und gibt am Ende eine Zusammenfassung der gefundenen Stellen aus.
import scrapy
class MySpider(scrapy.Spider):
name = "my_spider"
# Verhindert das Folgen auf verlinkte Seiten
allowed_domains = ['example.com']
start_urls = ['https://example.com']
# Eine Liste zur Speicherung der gefundenen Tags
found_empty_tags = []
def parse(self, response):
# Crawling-Seite zur Debug-Ausgabe
self.logger.info(f'Crawling page: {response.url}')
# Überprüfen, ob die Antwort eine HTML-Seite ist
if "text/html" in response.headers.get('Content-Type', b'').decode('utf-8'):
# Überprüfen auf leere <strong> und <b> Tags
empty_tags = response.xpath('//strong[not(normalize-space(.))] | //b[not(normalize-space(.))]')
# Falls leere Tags gefunden werden, diese speichern
if empty_tags:
found_on_page = {
'url': response.url,
'empty_tags': [tag.get() for tag in empty_tags]
}
self.found_empty_tags.append(found_on_page)
self.logger.info(f'Empty tags found: {found_on_page["empty_tags"]}')
# Crawle alle weiteren Links auf der Seite
for next_page in response.css('a::attr(href)').getall():
if next_page is not None:
yield response.follow(next_page, self.parse)
# Zusammenfassung nach dem Abschluss des Crawlings
def closed(self, reason):
self.logger.info('Summary of empty tags found:')
for entry in self.found_empty_tags:
self.logger.info(f'URL: {entry["url"]}')
self.logger.info(f'Empty tags: {entry["empty_tags"]}')
Die Stellen, an denen die gesuchten Tags gefunden wurden, werden vor der Zusammenfassung der Statistik angezeigt:
2024-10-03 20:53:36 [my_spider] INFO: Summary of empty tags found:
2024-10-03 20:53:36 [my_spider] INFO: URL: https://example.com/sub/
2024-10-03 20:53:36 [my_spider] INFO: Empty tags: ['<strong> </strong>']Anaconda-Navigator Umgebung für Scrapy einrichten
Öffnen Sie Anaconda Navigator, navigieren Sie nach Environments → Create und vergeben Sie einen Namen für die Umgebung (z.B. Scrapy). Aktivieren Sie die Checkbox: Python und klicken Sie auf Create:
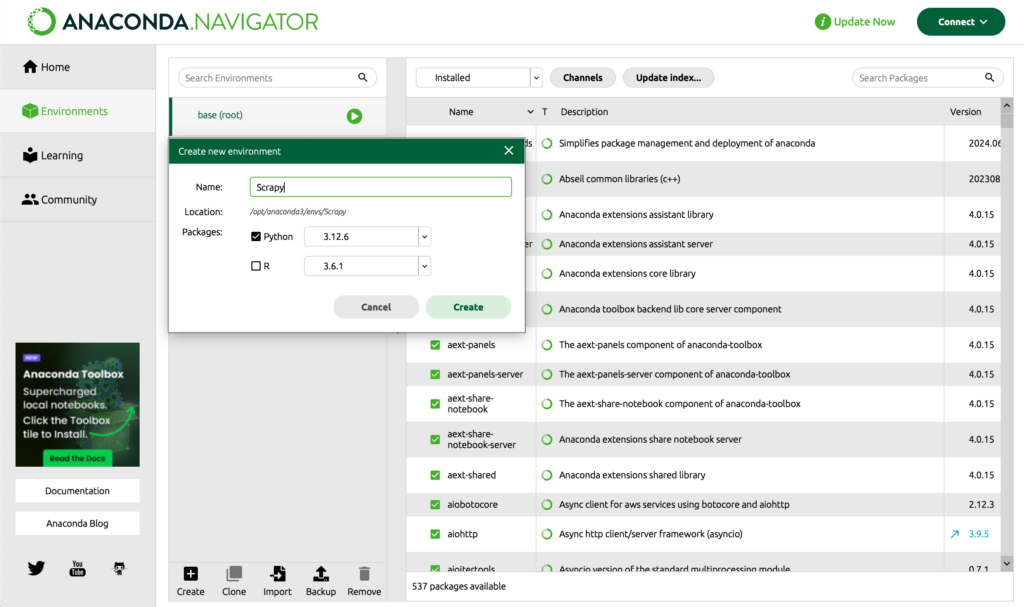
Klicken Sie auf die Schaltfläche Start ▹ und wählen Sie Open Terminal. Die Scrapy Umgebung wird in einer Konsole geladen. Installieren Sie das Scrapy Framework in der Umgebung mit folgendem Kommando:
$ conda install -c conda-forge scrapyDas folgende Kommando erstellt ein neues Scrapy Projekt mit dem Namen web_crawler:
$ scrapy startproject web_crawlerWechseln Sie in das Unterverzeichnis ./web_crawler/web_crawler/spiders und legen Sie dort ein Python-Script my_spider.py mit oben genannten Inhalt an. Passen Sie in den Zeilen 6 und 7 die gewünschte URL bzw. Domain an und führen Sie das Script aus:
$ scrapy crawl my_spider ![]()